
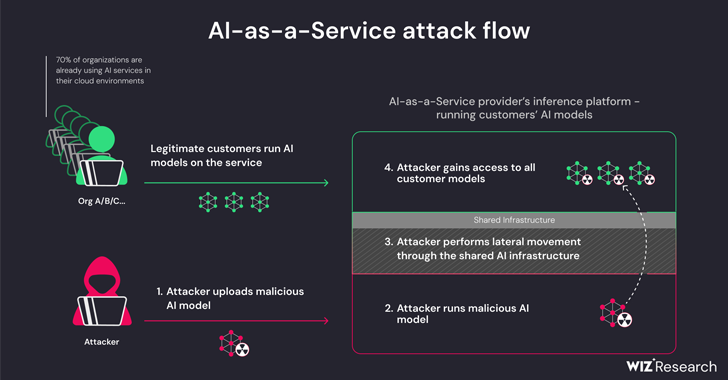
05 de abril de 2024Sala de prensaInteligencia artificial/ataque a la cadena de suministro Una nueva investigación ha descubierto que los proveedores de inteligencia artificial (IA) como servicio, como Hugging Face, son susceptibles a dos riesgos críticos que podrían permitir a los actores de amenazas aumentar privilegios y obtener beneficios cruzados. -Acceso de inquilino a los modelos de otros clientes, e incluso hacerse cargo de los canales de integración continua e implementación continua (CI/CD). «Los modelos maliciosos representan un riesgo importante para los sistemas de IA, especialmente para los proveedores de IA como servicio porque los atacantes potenciales pueden aprovechar estos modelos para realizar ataques entre inquilinos», dijeron los investigadores de Wiz Shir Tamari y Sagi Tzadik. «El impacto potencial es devastador, ya que los atacantes pueden acceder a millones de modelos y aplicaciones privados de IA almacenados en proveedores de IA como servicio». El desarrollo se produce cuando los canales de aprendizaje automático han surgido como un nuevo vector de ataque a la cadena de suministro, con repositorios como Hugging Face convirtiéndose en un objetivo atractivo para organizar ataques adversarios diseñados para recopilar información confidencial y acceder a entornos objetivo. Las amenazas tienen dos frentes y surgen como resultado de la adquisición compartida de la infraestructura de inferencia y de la adquisición compartida de CI/CD. Permiten ejecutar modelos que no son de confianza cargados en el servicio en formato pickle y hacerse cargo de la canalización de CI/CD para realizar un ataque a la cadena de suministro. Los hallazgos de la firma de seguridad en la nube muestran que es posible violar el servicio que ejecuta los modelos personalizados cargando un modelo no autorizado y aprovechando técnicas de escape de contenedores para escapar de su propio inquilino y comprometer todo el servicio, lo que permite de manera efectiva que los actores de amenazas obtengan información cruzada. acceso de inquilinos a los modelos de otros clientes almacenados y ejecutados en Hugging Face. «Hugging Face seguirá permitiendo al usuario inferir el modelo cargado basado en Pickle en la infraestructura de la plataforma, incluso cuando se considere peligroso», explicaron los investigadores. Básicamente, esto permite a un atacante crear un modelo PyTorch (Pickle) con capacidades de ejecución de código arbitrario al cargarlo y encadenarlo con configuraciones erróneas en Amazon Elastic Kubernetes Service (EKS) para obtener privilegios elevados y moverse lateralmente dentro del clúster. «Los secretos que obtuvimos podrían haber tenido un impacto significativo en la plataforma si estuvieran en manos de un actor malicioso», dijeron los investigadores. «Los secretos dentro de entornos compartidos a menudo pueden provocar acceso entre inquilinos y fuga de datos confidenciales. Para mitigar el problema, se recomienda habilitar IMDSv2 con límite de saltos para evitar que los pods accedan al servicio de metadatos de instancia (IMDS) y obtengan el rol de un nodo dentro del clúster. La investigación también encontró que es posible lograr la ejecución remota de código a través de un Dockerfile especialmente diseñado cuando se ejecuta una aplicación en el servicio Hugging Face Spaces, y usarlo para extraer y enviar (es decir, sobrescribir) todas las imágenes que están disponibles en un registro de contenedores interno. Hugging Face, en divulgación coordinada, dijo que ha abordado todos los problemas identificados. También insta a los usuarios a emplear modelos solo de fuentes confiables, habilitar la autenticación multifactor (MFA) y abstenerse de usar pickle. archivos en entornos de producción: «Esta investigación demuestra que el uso de modelos de IA que no son de confianza (especialmente los basados en Pickle) podría tener graves consecuencias para la seguridad», dijeron los investigadores. «Además, si pretende permitir que los usuarios utilicen modelos de IA que no son de confianza en su entorno, es extremadamente importante asegurarse de que se ejecuten en un entorno aislado». La divulgación sigue a otra investigación de Lasso Security de que es posible que modelos de IA generativa como OpenAI ChatGPT y Google Gemini distribuyan paquetes de códigos maliciosos (e inexistentes) a desarrolladores de software desprevenidos. En otras palabras, la idea es encontrar una recomendación para un paquete no publicado y publicar un paquete troyanizado en su lugar para propagar el malware. El fenómeno de las alucinaciones de paquetes de IA subraya la necesidad de tener cuidado al confiar en modelos de lenguaje grandes (LLM) para soluciones de codificación. La empresa de inteligencia artificial Anthropic, por su parte, también ha detallado un nuevo método llamado «jailbreaking de muchos disparos» que puede usarse para eludir las protecciones de seguridad integradas en los LLM para producir respuestas a consultas potencialmente dañinas aprovechando la ventana de contexto de los modelos. «La capacidad de ingresar cantidades cada vez mayores de información tiene ventajas obvias para los usuarios de LLM, pero también conlleva riesgos: vulnerabilidades de jailbreak que explotan la ventana de contexto más larga», dijo la compañía a principios de esta semana. La técnica, en pocas palabras, implica introducir una gran cantidad de diálogos falsos entre un humano y un asistente de IA dentro de un solo mensaje para el LLM en un intento de «dirigir el comportamiento del modelo» y responder a consultas que de otro modo no haría (por ejemplo, , «¿Cómo construyo una bomba?»). ¿Encontró interesante este artículo? Síguenos en Twitter y LinkedIn para leer más contenido exclusivo que publicamos.
Deja una respuesta