
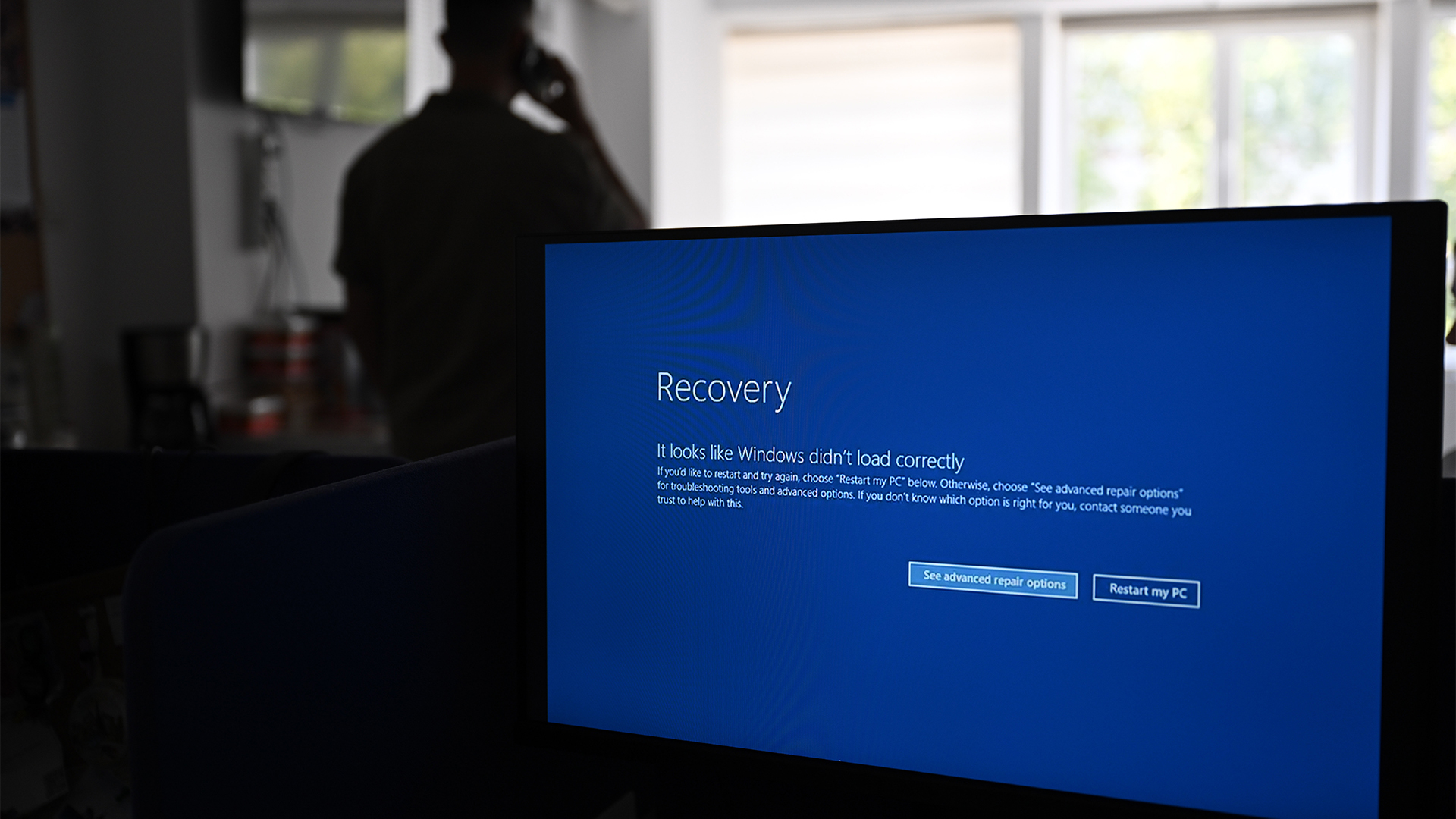
Los expertos advierten que las interrupciones generalizadas de TI causadas por una actualización defectuosa de CrowdStrike requerirán un largo período de reparación, ya que la interrupción continúa causando estragos a nivel mundial. En la mañana del 19 de julio, las organizaciones en Australia e India comenzaron a advertir que estaban experimentando interrupciones significativas con sus máquinas Windows. Esto se convirtió en una disrupción global cuando el resto del mundo se despertó para comenzar su día de trabajo, con bancos, aerolíneas, emisoras y más enfrentándose a la temida pantalla azul de la muerte (BSOD) de Windows. CrowdStrike ha confirmado desde entonces que es la fuente del problema, y el CEO George Kurtz reveló a través de X que el incidente fue causado por un «defecto encontrado en una única actualización de contenido para hosts de Windows». Maxine Holt, directora senior de ciberseguridad en la firma de investigación Omdia, describió la escala del problema, que algunos llaman la mayor interrupción de TI de todos los tiempos. «La crisis global de interrupciones de TI está aumentando y las organizaciones de todo el mundo están en modo de lucha total, implementando desesperadamente soluciones alternativas para mantener sus negocios a flote», dijo.declaró. «CrowdStrike admite un ‘defecto encontrado en una única actualización de contenido para hosts de Windows’ y está trabajando febrilmente con los clientes afectados», agregó Holt. Reciba nuestras últimas noticias, actualizaciones de la industria, recursos destacados y más. Regístrese hoy para recibir nuestro informe GRATUITO sobre ciberdelito y seguridad de IA, recientemente actualizado para 2024. Adam Leon Smith, miembro de BCS y experto en ciberseguridad, dijo que el incidente subraya el difícil acto de equilibrio que deben hacer los proveedores de software entre lanzar actualizaciones de manera oportuna, al mismo tiempo que se aseguran de no terminar dañando los sistemas que se pretenden proteger. «La gente quiere implementar actualizaciones de seguridad lo más rápido posible porque eso ayuda a prevenir lo que llamamos ataques de ‘día cero’; «Esas son nuevas formas en las que se encuentran actores para comprometer los sistemas», explicó. «Aquí hay un equilibrio entre la velocidad de garantizar que los sistemas estén protegidos contra nuevas amenazas y la debida diligencia realizada para proteger la resiliencia del sistema y evitar que sucedan cosas como este incidente». Las soluciones alternativas para la interrupción de TI serán una «pesadilla» para los clientes En una declaración reconociendo el incidente, CrowdStrike aseguró a los usuarios que su equipo está completamente movilizado para garantizar la seguridad y la estabilidad de los clientes, proporcionando una serie de soluciones alternativas para hosts individuales y sistemas de nube pública. Leon Smith agregó que, aunque las correcciones han comenzado a aparecer desde que comenzó la interrupción, debido a que está obligando a tantas máquinas a entrar en bucles de arranque o en el BSOD, podría pasar algún tiempo antes de que la mayoría de los sistemas vuelvan a estar en línea. «En algunos casos, la solución puede aplicarse muy rápidamente, pero como tiene que aplicarse a tantas computadoras en todo el mundo, eso puede llevar más tiempo de lo que parece», dijo. «Pero si las computadoras han reaccionado de una manera que significa que están entrando en pantallas azules y bucles infinitos, puede ser difícil restaurarlas, y eso podría llevar días y semanas». Holt se hizo eco de las preocupaciones de Leon Smith, confesando que la solución alternativa será difícil de implementar para muchos clientes. «La solución alternativa, que implica arrancar en modo seguro, es una pesadilla para los clientes de la nube. Las empresas que dependen de la nube se enfrentan a graves interrupciones. Pero Smith señaló que las cosas podrían haber sido mucho peores, señalando que un problema similar que afectara a Linux habría causado problemas mucho más importantes en virtud de su uso en sistemas y servicios más críticos. «Tenemos que darnos cuenta de que esto podría haber sido mucho peor. Microsoft Windows no es el principal sistema operativo utilizado para sistemas de misión crítica. Es Linux». Steve Sands, presidente del Grupo de especialistas en seguridad de la información de BCS, dijo que las empresas deberían centrarse en volver a poner en línea los sistemas en lugar de tratar de entender cómo se produjo la interrupción. Además, enfatizó que el incidente debería servir como recordatorio de lo importante que es la resiliencia del software. «Espero sinceramente que los problemas de CrowdStrike de hoy generen conciencia y creen una urgencia muy necesaria para continuar esta conversación vital… Mi consejo sería centrarse en restaurar sus propios sistemas de TI (siguiendo el consejo de los proveedores) y dejar que los proveedores y la industria trabajen para comprender cómo sucedió esto y aprender las lecciones».
Deja una respuesta